

During our experiments, each pixel on the detector gives us a datapoint, with the pixel collecting all photons that arrive across its surface. However, since detectors have many more pixels than the amount of datapoints we can realistically use, we usually perform some sort of averaging or binning procedure, grouping proximate pixels together to form a single datapoint. It is an important procedure, and so I have talked about this many times before (here, here, here, here, here and here). Today, I’d like to discuss what we do specifically with our scattering vector Q.

The most common procedure involves defining new boundaries. Pixels with q-values (e.g. centre 0f mass) that fall within a pair of these bounds are considered part of that bin. We then calculate the mean intensity, propagate the uncertainty on the intensity, and calculate the standard error on the mean as well for a second measure of uncertainty (see Figure 1, v.1).
A second version of this method, the pixel-splitting method, works slightly differently. It does not deposit all the intensity of a given pixel into a single bin, but separates the intensity between its two neighbouring bin means, with a ratio dependent on the distance from the pixel centre to the means (Figure 1, v.2). The closer the pixel centre to a given bin mean, the more intensity ends up in there. This makes it a bit more cumbersome to calculate the uncertainty statistics, but it’s not impossible.
Historically, we have been less bothered by the value of Q assigned to the bin. In v.1, we take the mean Q value between the bin edges. In v.2, we only work with predefined bin edges. However, our work estimating uncertainty budgets in Q, and the larger-than-expected effect on a Q-shift on the data, has shown that we might need to be more accurate about what we do with it.
So we’re now considering the following, and experimenting with its effect: We do the binning in the traditional (v.1) way, but we use the actual pixel Q values to calculate the mean Q and the standard error on the mean Q for each bin (v.3). We can even take this one step further. Every pixel is defined not just by its centre-of-mass Q, but also by the pixel width 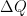
This way, we should end up with more accurate Q values on our binned data, with bonus uncertainties. This is particularly effective in areas with a small number of pixels, typically close to the beamstop in pinhole-collimated instruments. I don’t know if we can somehow take the Q uncertainty into account during the fitting procedure, but if we want to, it’s nice to have them there already.
As usual, please leave thoughts below!
Brian. I would not call this Q uncertainty, there is nothing uncertain on this. Personally, I call this Q resolution… It is certain for your Q to have for each Q “bin” a “width” given by physical pixel dimension – but that may be just small component of data Q resolution. I believe that Delta-Q should also (at least) include the beam size — potentially even detector bin cross talk, wavelength distribution, etc. and convolute all of that together. I remember paper on this (by John Barker?) but cannot get my hands on quickly…
Personally I believe you may be overthinking it for current giant pixel number SAXS instruments – by the time you convolute pixel size with beam size and Q binning, it does not matter what method you used to allocate the intensity to pixels. SANS guys have been doing pixel splitting at small angle pixels for years, if I recall correctly. Check with them.
Nika, for your information, uses bin centers for where the intensity is assigned (no pixel splitting). It also, per user choice, defines new log-q spaced Q bins (its bit more complicated here…) so the number of Q points is sensibly matched (per user choice) to complexity of data. This reduces the number of Q points at high-q while keeping all points at low-q – basically log-q smoothing. Helps subsequent modeling a lot! It then calculates for each Q point (bin) Q resolution (Delta-Q) which is convolution of: pixel size & beam size & the new Q-bin width – wavelength smearing and pixel cross talk are ignored.
Q resolution can be used in Irena Modeling package (actually, number of different Q resolution definitions, see here: http://saxs-igorcodedocs.readthedocs.io/en/latest/Irena/Modeling.html#modeling-qresolution) to smear the model data for fitting. I found it in testing useful and important ONLY for nearly perfect monodispersed systems. At least once or twice I found it critical to have meaningful Q resolution… But any significant polydispersity in the samples (95%+ of my samples) and Q resolution has minimal to no impact. Most other Irena models (Unified fit, Size distribution,…) really do not need to deal with Q resolution.
So yes, it can be real and it can be used… It is computationally expensive and ugly in code. In my experience rarely needed, but in those cases you cannot get fit without proper Q resolution.
Hello Jan, thank you very much for the detailed thoughts on the matter.
Let me quickly reply before I need to fly on a few things that come to mind..
About the computationally expensive part: We’re already calculating the mean and variance of the intensities of all pixels in a bin. Applying the exact same procedure to the q-values instead of the intensities of all pixels in the bin is not much extra effort.
I agree that “uncertainty” is not a nice term. For a single, finite-width pixel it is correct: it detects a photon that may have arrived anywhere on its surface, therefore we are not quite sure about the photon’s actual position –> we have an “uncertainty” on its position. That propagates like statistical uncertainties through any binning procedures.
As for terms, “Error” isn’t nice either, since it indicates we’re wrong about something. “Resolution” has been hijacked by some to mean the smallest q (or largest dimension) we can measure, or something related to the beam dimensions, so is somewhat similar, but not quite appropriate either. “standard deviation” might work and its meaning is clear, but is a bit cumbersome to use.
As for smearing effects, yes, we might want to take that up in the Q uncertainty, but I’d prefer having it separate. If we have it separate, we can treat it in more detail. If it’s folded with the other Q uncertainty contributors, there’s no way to get it out again. I still have hopes that we can use the beam profile in the fitting procedure to get better fitting results (the inverse of desmearing), in which case we may be able to compensate for its contribution to the uncertainty.
Tough topics, but fun. As you say, practically unlikely to be necessary. But if we can do things right straight away, we have fewer reasons to bang our heads against the walls later.